Abstract
Enormous availability of web pages containing information leaves user in confusion of which webpage to trust and which link provides the right information. This paper provides a survey of the most relevant studies carried out in regard of ranking web pages. First, it introduces the problem of “Veracity” , conformity to truth. It then goes on to list the most common algorithms that have been used to resolve the problem of conformity to truth. Finally, this analysis provides a way to guide future research in this field.
Keywords: Trustworthiness, ranking
The world wide web has become the most important information source. Everyone uses WWW for searching any information about any particular thing or keyword. It is very common that the results we obtain provide a lot of useless pages. Different websites generally provide conflicting information about same object. It becomes quite difficult to decide about the correctness of information we get from search engines. In most cases, users believe that the topmost links provided by any search engine provide trustworthy results without regard to exceptions. But there is no surity for the accuracy of information present on the internet. Moreover, various websites generally provide inconsistent and conflicting information for same object, like different specifications for same product. For instance a user is interested in knowing the height of Mount Everest and queries the search engine with “The height of Mount Everest is?” Among the top results, user will find the following facts: some websites say 29,055 feet, other websites say 29,028 feet, another one says 29,002 feet, and rest say 29,027 feet. It becomes difficult to decide which answer is correct and which fact should user trust?[1] . The question is how to decide the right information and how to decide the trustworthiness of any website. The problem is known as ‘Veracity’.
It becomes quite difficult for the user to decide which website to trust for the correctness of information. The resultant pages of any search engine must be ranked according to decreasing level of trustworthiness.
To resolve this problem, different algorithms have been developed. The existing algorithm Page Rank which is used by Google, uses link structure of the web page[2]. Another algorithm exists known as Weighted PageRank(WPR) Algorithm. It assigns larger rank values to more popular webpages rather than dividing the rank value of a webpage evenly among its outlink pages[3]. Each outlink page gets a value corresponding to its popularity (count of inlinks and outlinks). Voting is another approach to rank web pages which uses the count of votes from one webpage to another and ranks webpages with respect to the count results. Authority-Hub analysis is also used for ranking webpages. It works on the idea of high authorities and popularity of websites. These approaches identify important web pages as per user’s interest but popularity of webpages does not guarantee accuracy of information. A less popular website may provide more useful and accurate information as compared to more popular websites. All of them use iterative approaches, in which same trustworthiness value is given to all data sources, and iteratively evaluate the confidence of every fact and then propagate back to the data sources. Tagrank, Distancerank, Timerank, Relation based algorithm, Weighted link rank.
This paper surveys the most relevant algorithms proposed in this field as solution to the problem of ranking the web pages.
The rest of this paper is organized as follows. Section 1 discusses different techniques for ranking web pages. Section 2 presents the analysis and section 3 contains a brief conclusion.
2.1 PageRank:
PageRank is a method of measuring a page’s “significance”[2]. PageRank is based on the idea that good pages always reference good pages. PageRank’s theory says that if Page A links to Page B, then that link is counted as one vote for page B. If any link pointing to a page is important then it is counted as a strong vote. If links pointing to a page are important then the outlinks of that page also become important.




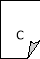




Fig1 : A and B are backlinks of C
In this figure, A and B are backlinks of C and C is the backlink of D and E.
Assume A, B, C and D are four webpages. Self links or multiple links from one page to another page, are ignored. Initially same PageRank value is assigned to all pages. Originally in PageRank, the total number of webpages was the sum of PageRank over all pages. However, advanced versions of PageRank use a probability distribution between 0 and 1. Hence the initial value for each page mentioned above is 0.25.
In the next iteration the PageRank is transferred from a given page to its outbound links is equally divided among them.
If in the system links were from pagesB,C, andDtoA then each link would transfer probability distribution of 0.25 PageRank toAon next iteration, for a total of 0.75.
PR(A) = PR(B)+PR(C)+PR(D)
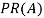 =
= 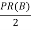 +
+ 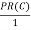 +
+ 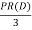
In general case, for any page u the PageRank value can be stated as:
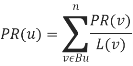
L(v) – number of outlinks of pagev.
Bu – set containing all pages that links to pageu.
The PageRank value for a pageuis dependent on the PageRank values for each pagevcontained in the setBu, divided by the numberL(v) of outlinks of pagev.
2.2 Weighted Pagerank:
WPR algorithm is an extension to the ordinary PageRank algorithm. Limitation of existing algorithms HITS and PageRank is that both algorithms deal all links uniformly when distributing rank scores[3]. WPR considers the significance of both inlinks and outlinks of the webpages and on the basis of popularity of pages, the rank scores are distributed. PageRank algorithm divides the rank values of any page evenly amongst its outlink pages, while WPR assigns higher rank values to more popular webpages.
Considering the significance of webpages, the original PageRank equation is modified as [3]:
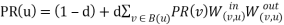 [4]
[4]
2.3 Distancerank:
Distancerank is an intelligent ranking algorithm proposed by Ali Mohammad Zareh Bidoki and Nasser Yazdani[11]. This algorithm is based on reinforcement learning such that the distance between pages is considered as a punishment factor. The distance is defined as the number of ‘‘average clicks’’ between two pages. The distance dj of page j is computed as :
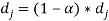 +α*mini(log(O(i))+di)[11]
+α*mini(log(O(i))+di)[11]
where i is a member of pages that point to j and O(i) shows out degree of i and a is the learning rate of the user[1].
2.4 Hyperlink Induced Topic Search (HITS):
The HITS algorithm is also known as “hubs and authorities” is a link analysis algorithm.
HITS divides the sites of a query between “hubs” and “authorities” for ranking webpages. Links to authorities are contained in hubs, while hubs point to authorities [6].



Hubs Authorities
HITS assigns two values to a webpage: a hub weight and an authority weight. These weights are defined recursively. A high authority weight occurs if webpages with high hub weights are pointing it. Similarly, a higher hub weight occurs if the webpage points to large webpages with high authority weights. Thus, itidentifies good authorities and hubs for any query. HITS works on the concept that if the creator of webpage p has a link to webpage q then p has some authority on q[6].
2.5 TimeRank:
Time Rank algorithm proposed by H Jiang et al improves the rank score of web pages by using the visit time of web pages. This algorithm is supposed to be a combination of link structure and content[9].
Pr (T(i)|q) = Pr (T(i)) + Pr (q|T(i))
Ti ï‚® means topic i of each page.
Pr (T (i)) – means the section of pages belonging to topic i in the whole page set.
Pr (Ti | q) – means the probability of query q related to topic i.
2.6 Web Page Ranking using link attributes:
Weighted Links Rank (WLRank) assigns the value R(i), known as Ranking value, to page i with the following equations[12]:
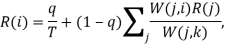
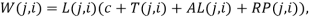
Where, given a link from page j to page i we have:
Different algorithms for ranking webpages have been studied and the analysis is presented in the following table:
|
Algorithms |
Main Technique |
Approach |
Input Parameter |
Applicability |
Importance |
Limitations |
|
PageRank |
Web Structure Mining |
Compute scores at time when indexing of the pages is done. |
Backlinks |
Less as in this algorithm ranking is done on the basis of indexing time. |
High as it considers backlinks. |
Results come at indexing time not at query time. |
|
Weighted PageRank |
Web Structure Mining |
Input and output links are used to evaluate weight of webpage & then importance of webpage is decided. |
forward links and Backlinks |
Less as in this algorithm ranking is based on evaluation of weight of the webpage at indexing time. |
High as it sorts pages according to page’s importance. |
Relevancy of webpage is ignored. |
|
HITS |
Web Content Mining, Web Structure Mining |
Computes hubs and authorities of webpages |
Backlinks, Forward links, Content |
More, as it uses hyperlinks and content of the page |
Moderate as it utilizes hub and authorities score |
Efficiency problem and sometimes topic drift |
|
DistanceRank |
Web Structure Mining |
Based on logarithmic distance between webpages and reinforcement learning |
Forward links |
Moderate as it uses hyperlinks |
High as it uses distance between pages |
Large calculations involved to calculate distance vector |
|
TimeRank |
Web Usage Mining |
Visiting time is added to original page rank score of page |
Standard Page Rank and server log |
High as original rank is updated according to visitor time |
High as it considers most recently visited page |
Large calculations involved to calculate distance vector |
|
Web Page Ranking using link attributes |
Web Structure Mining,Web Content Mining |
Gives significance to web links on basis of 3 attributes: Tag where the link is contained, relative position in the page and length of the anchor text |
Backlinks, Forward links, Content |
More, as it considers relative position of the links in web pages |
Not concrete |
Relative position in the page was not so effective because logical position does not always match physical position |
References:
[1] X. Yin, J. Han, and P. S. Yu, “Truth Discovery with Multiple Conflicting Information Providers on the Web”, IEEE
Transactions On Knowledge And Data Engineering, Vol. 20, No. 6, June 2008.
[2] C. Ridings and M. Shishigin, “Pagerank Uncovered”, Technical Report, 2002.
[3]Wenpu Xing and Ali Ghorbani, “Weighted PageRank Algorithm”, In proceedings of the 2rd Annual Conference on Communication Networks & Services Research, PP. 305-314, 2004.
[4]Wenpu Xing and Ali Ghorbani, “Weighted PageRank Algorithm”, In proceedings of the 2rd Annual Conference on Communication Networks & Services Research, PP. 305-314, 2004.
[5] Geeta R. Bharamagoudar , Shashikumar G.Totad and Prasad Reddy PVGD, “ Literature Survey on Web Mining” IOSR Journal of Computer Engineering ,Issue 4 (Sep-Oct. 2012).
[6] Jon Kleinberg, “Authoritative Sources in a Hyperlinked Environment”, In proceedings of the ACM-SIAM Symposium on Discrete Algorithms, 1998.
[7] Lin-Tao Lv, Li-Ping Chen, Hong-Fang Zhou, “An improved topic relevance algorithm for vertical search engines,” ICWAPR ’08, Hong Kong, pp. 753-757, Aug 2008.
[8] H Jiang et al., “TIMERANK: A Method of Improving Ranking Scores by Visited Time”, In proceedings of the Seventh International Conference on Machine Learning and Cybernetics, Kunming, 12-15 July 2008.
[9] S. Chakrabarti, B. Dom, D. Gibson, J. Kleinberg, R. Kumar, P.Raghavan, S. Rajagopalan, A. Tomkins, “Mining the Link Structure of the World Wide Web”, IEEE Computer Society Press, Vol 32, Issue 8 pp. 60 – 67, 1999.
[10] Fabrizio Lamberti, Andrea Sanna and Claudio Demartini , “A Relation-Based Page Rank Algorithm for. Semantic Web Search Engines”, In IEEE Transaction of KDE, Vol. 21, No. 1, Jan 2009.
[11] Ali Mohammad Zareh Bidoki and Nasser Yazdani, “DistanceRank: An Iintelligent Ranking Algorithm for Web Pages”, Information Processing and Management, 2007.
[12] Ricardo Baeza-Yates and Emilio Davis ,”Web page ranking using link attributes” , In proceedings of the 13th international World Wide Web conference on Alternate track papers & posters, PP.328-329, 2004.
[13] Milan Vojnovic et al., “Ranking and Suggesting Popular Items”, In IEEE Transaction of KDE, Vol. 21, No. 8, Aug 2009.
[14] Fang Liu, Clement Yu, Weiyi Meng, “Personalized Web Search for Improving Retrieval Effectiveness”, IEEE transactions on knowledge and data engineering, 16 (1) January 2004.
[15] Gr´egoire Burel, Amparo E. Cano, Matthew Rowe, and Alfonso Sosa “Representing, Proving and Sharing Trustworthiness of Web Resources Using Veracity” Springer-Verlag Berlin Heidelberg 2010.
Delivering a high-quality product at a reasonable price is not enough anymore.
That’s why we have developed 5 beneficial guarantees that will make your experience with our service enjoyable, easy, and safe.
You have to be 100% sure of the quality of your product to give a money-back guarantee. This describes us perfectly. Make sure that this guarantee is totally transparent.
Read moreEach paper is composed from scratch, according to your instructions. It is then checked by our plagiarism-detection software. There is no gap where plagiarism could squeeze in.
Read moreThanks to our free revisions, there is no way for you to be unsatisfied. We will work on your paper until you are completely happy with the result.
Read moreYour email is safe, as we store it according to international data protection rules. Your bank details are secure, as we use only reliable payment systems.
Read moreBy sending us your money, you buy the service we provide. Check out our terms and conditions if you prefer business talks to be laid out in official language.
Read more